|
AnythingLLM:基于RAG方案构专属私有知识库(开源|高效|可定制)一、前言 继OpenAI和Google的产品发布会之后,大模型的能力进化速度之快令人惊叹,然而,对于很多个人和企业而言,为了数据安全不得不考虑私有化部署方案,从GPT-4发布以来,国内外的大模型就拉开了很明显的差距,能够实现的此路径无非就只剩下国内的开源大模型可以选择了。而现阶段切入大模型应用落地最合适的方案依然是结合大模型基于RAG检索增强来实现知识库的检索和生存。从而构建个人或者企业私有化的本地知识库。 你只需要将本地私有的 PDF、Word 文档和文本文件嵌入到本地向量库,连接上LLM,然后就可以通过对话、搜索的方式进行回答问题、提供见解,甚至生成摘要。 接下来我们就介绍一下 Mintplex Labs 的两个高度创新的开源项目。它们是 AnythingLLM(一种企业级解决方案,专为创建自定义 ChatBot(包括 RAG 模式)而设计)和 Vector Admin(一种用于有效管理多个向量存储的复杂管理 GUI)。 AnythingLLM 不仅仅是另一个聊天机器人。它是一个全栈应用程序,这意味着它融合了从数据处理到用户界面的所有技术优势。最好的部分?它是开源且可定制的。这意味着如果您有技能,您可以根据自己的喜好进行调整。或者,如果您像我一样更喜欢现成的东西,那么它开箱即用,效果非常好。 二、概述2.1、AnythingLLM 介绍AnythingLLM 是 Mintplex Labs Inc. 开发的一款开源 ChatGPT 等效工具,用于在安全的环境中与文档等进行聊天,专为想要使用现有文档进行智能聊天或构建知识库的任何人而构建。 AnythingLLM 能够把各种文档、资料或者内容转换成一种格式,让LLM(如ChatGPT)在聊天时可以引用这些内容。然后你就可以用它来和各种文档、内容、资料聊天,支持多个用户同时使用,还可以设置谁能看或改哪些内容。 支持多种LLM、嵌入器和向量数据库。 2.2、AnythingLLM 特点- 多用户支持和权限管理:允许多个用户同时使用,并可设置不同的权限。
- 支持多种文档类型:包括 PDF、TXT、DOCX 等。
- 简易的文档管理界面:通过用户界面管理向量数据库中的文档。
- 两种聊天模式:对话模式保留之前的问题和回答,查询模式则是简单的针对文档的问答
- 聊天中的引用标注:链接到原始文档源和文本。
- 简单的技术栈,便于快速迭代。
- 100% 云部署就绪。
- “自带LLM”模式:可以选择使用商业或开源的 LLM。
- 高效的成本节约措施:对于大型文档,只需嵌入一次,比其他文档聊天机器人解决方案节省 90% 的成本。
- 完整的开发者 API:支持自定义集成。
2.3、支持的 LLM、嵌入模型和向量数据库- LLM:包括任何开源的 llama.cpp 兼容模型、OpenAI、Azure OpenAI、Anthropic ClaudeV2、LM Studio 和 LocalAi。
- 嵌入模型:AnythingLLM 原生嵌入器、OpenAI、Azure OpenAI、LM Studio 和 LocalAi。
- 向量数据库:LanceDB(默认)、Pinecone、Chroma、Weaviate 和 QDrant。
2.4、技术概览整个项目设计为单线程结构,主要由三部分组成:收集器、前端和服务器。 - collector:Python 工具,可快速将在线资源或本地文档转换为 LLM 可用格式。
- frontend:ViteJS + React 前端,用于创建和管理 LLM 可使用的所有内容。
- server:NodeJS + Express 服务器,处理所有向量数据库管理和 LLM 交互。
首先,收集器是一个实用的Python工具,它使用户能够快速将来自在线资源(如指定的YouTube频道的视频、Medium文章、博客链接等)或本地文档中的可公开访问数据转换为LLM可用的格式。该应用程序的前端采用了vitejs 和React进行构建,通过Node.js和Express服务器处理所有LLM交互和VectorDB管理。这种设计使得用户能够在直观友好的界面中进行操作,并且通过高效的服务器架构实现快速响应和管理大规模的数据。 三、AnythingLLM 部署接下来开始完成本地模型(特别是文本嵌入和生成)以及向量存储的部署,所有这些都旨在与上述解决方案无缝集成。为此,我们将结合使用 LocalAI 和 Chroma。 3.1、安装 Chroma Vectorstore该过程首先克隆官方存储库并启动 Docker 容器。
[color=rgb(51, 102, 153) !important]复制代码
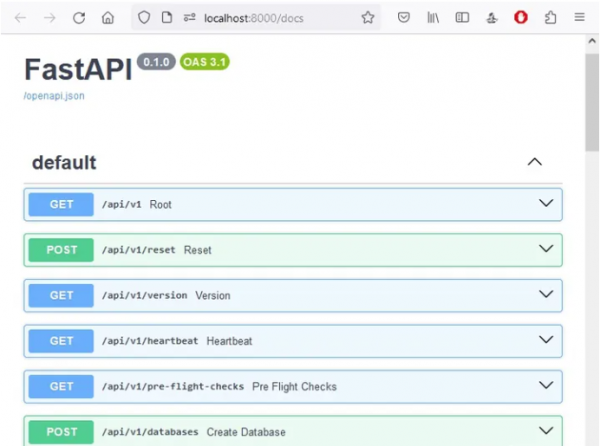
为了验证向量存储的可用性,我们连接到其 API 文档,网址为:http://localhost:8000/docs 使用此 API,我们继续创建一个新集合,恰当地命名为“playground”。 - curl -X 'POST' 'http://localhost:8000/api/v1/collections?tenant=default_tenant&database=default_database'
- -H 'accept: application/json'
- -H 'Content-Type: application/json'
- -d '{ "name": "playground", "get_or_create": false}'
- curl http://localhost:8000/api/v1/collections
- [
- {
- "name": "playground",
- "id": "0072058d-9a5b-4b96-8693-c314657365c6",
- "metadata": {
- "hnsw:space": "cosine"
- },
- "tenant": "default_tenant",
- "database": "default_database"
- }
- ]
LocalAi 是一个功能齐全的 CLI 应用程序,你可以运行它来轻松启动 API 服务器,以便与 HuggingFace 上找到的开源模型聊天以及运行嵌入模型! 接下来,我们的重点转移到建立 LocalAI Docker 容器。 - git clone https://github.com/go-skynet/LocalAI
- cd LocalAI
- docker compose up -d --pull always
一旦容器运行,我们就开始下载、安装和测试两个特定模型。 我们的第一个模型是来自 Bert 的句子转换器嵌入模型:MiniLM L6。 - curl http://localhost:8080/models/apply
- -H "Content-Type: application/json"
- -d '{ "id": "model-gallery@bert-embeddings" }'
- curl http://localhost:8080/v1/embeddings
- -H "Content-Type: application/json"
- -d '{ "input": "The food was delicious and the waiter...",
- "model": "bert-embeddings" }'
- {
- "created": 1702050873,
- "object": "list",
- "id": "b11eba4b-d65f-46e1-8b50-38d3251e3b52",
- "model": "bert-embeddings",
- "data": [
- {
- "embedding": [
- -0.043848168,
- 0.067443006,
- ...
- 0.03223838,
- 0.013112408,
- 0.06982294,
- -0.017132297,
- -0.05828256
- ],
- "index": 0,
- "object": "embedding"
- }
- ],
- "usage": {
- "prompt_tokens": 0,
- "completion_tokens": 0,
- "total_tokens": 0
- }
- }
- curl http://localhost:8080/models/apply
- -H "Content-Type: application/json"
- -d '{ "id": "huggingface@thebloke__zephyr-7b-beta-gguf__zephyr-7b-beta.q4_k_s.gguf",
- "name": "zephyr-7b-beta" }'
- curl http://localhost:8080/v1/chat/completions
- -H "Content-Type: application/json"
- -d '{ "model": "zephyr-7b-beta",
- "messages": [{
- "role": "user",
- "content": "Why is the Earth round?"}],
- "temperature": 0.9 }'
- {
- "created": 1702050808,
- "object": "chat.completion",
- "id": "67620f7e-0bc0-4402-9a21-878e4c4035ce",
- "model": "thebloke__zephyr-7b-beta-gguf__zephyr-7b-beta.q4_k_s.gguf",
- "choices": [
- {
- "index": 0,
- "finish_reason": "stop",
- "message": {
- "role": "assistant",
- "content": "\nThe Earth appears round because it is
- actually a spherical body. This shape is a result of the
- gravitational forces acting upon it from all directions. The force
- of gravity pulls matter towards the center of the Earth, causing
- it to become more compact and round in shape. Additionally, the
- Earth's rotation causes it to bulge slightly at the equator,
- further contributing to its roundness. While the Earth may appear
- flat from a distance, up close it is clear that our planet is
- indeed round."
- }
- }
- ],
- "usage": {
- "prompt_tokens": 0,
- "completion_tokens": 0,
- "total_tokens": 0
- }
- }
成功安装模型和向量存储后,我们的下一步是部署 AnythingLLM 应用程序。为此,我们将利用 Mintplex Labs 提供的官方 Docker 镜像 - docker pull mintplexlabs/anythingllm:master
- export STORAGE_LOCATION="/var/lib/anythingllm" && \
- mkdir -p $STORAGE_LOCATION && \
- touch "$STORAGE_LOCATION/.env" && \
- docker run -d -p 3001:3001 \
- -v ${STORAGE_LOCATION}:/app/server/storage \
- -v ${STORAGE_LOCATION}/.env:/app/server/.env \
- -e STORAGE_DIR="/app/server/storage" \
- mintplexlabs/anythingllm:master
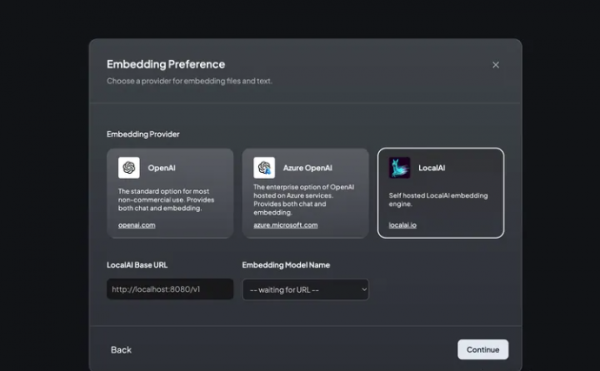
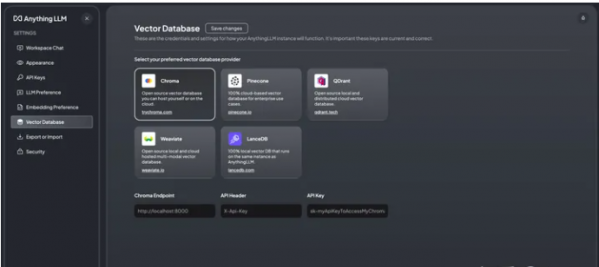
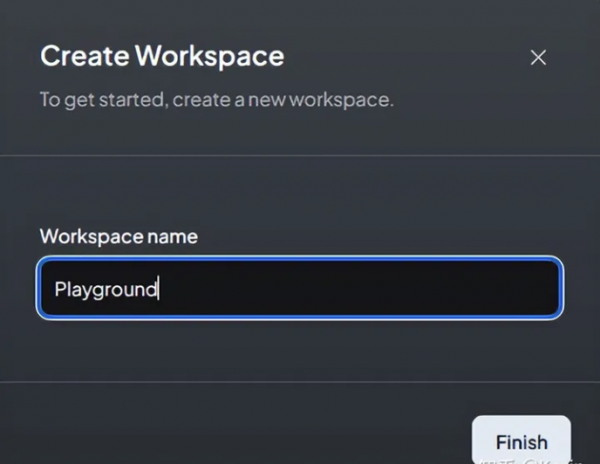
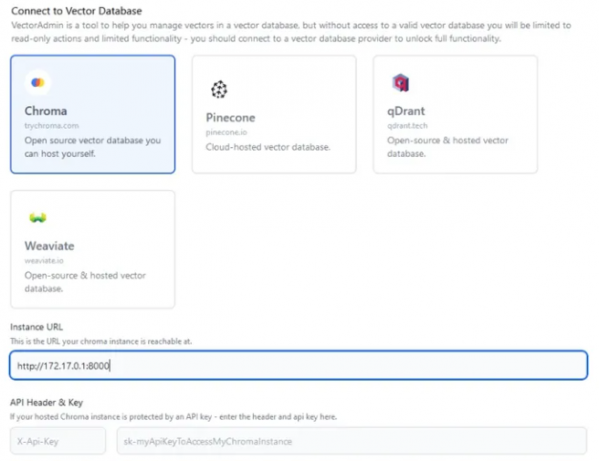
通过导航到 http://localhost:3001 可以访问应用程序,我们可以在其中使用直观的 GUI 开始配置过程。 在配置中,我们选择 LocalAI 后端,可通过 http://127.0.0.1:8080/v1 URL 访问,并集成 Zephyr 模型。值得注意的是,AnythingLLM 还支持其他后端,例如 OpenAI、Azure OpenAI、Anthropic Claude 2 和本地可用的 LM Studio。 接下来,我们将嵌入模型与相同的 LocalAI 后端保持一致,确保系统具有凝聚力。 接下来,我们选择 Chroma 向量数据库,使用 URL http://127.0.0.1:8000。值得一提的是,AnythingLLM 还与其他向量存储兼容,例如 Pinecone、QDrant、Weaviate 和 LanceDB。 AnythingLLM 的自定义选项包括添加徽标以个性化实例的可能性。但是,为了本教程的简单起见,我们将跳过这一步。同样,虽然有配置用户和权限管理的选项,但我们将继续进行简化的单用户设置。 然后,我们继续创建一个工作区,恰当地命名为“Playground”,反映了我们早期 Chroma 系列的名称。 AnythingLLM 起始页旨在通过类似聊天的界面向用户提供初始说明,并可以灵活地根据特定需求定制此内容。 
从我们的“Playground”工作区,我们可以上传文档,进一步扩展我们的设置的功能。 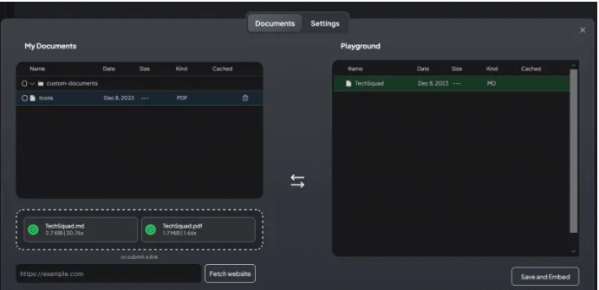
我们监控日志以确认 AnythingLLM 有效地将相应的向量插入到 Chroma 中。 - Adding new vectorized document into namespace playground
- Chunks created from document: 4
- Inserting vectorized chunks into Chroma collection.
- Caching vectorized results of custom-documents/techsquad-3163747c-a2e1-459c-92e4-b9ec8a6de366.json to prevent duplicated embedding.
- Adding new vectorized document into namespace playground
- Chunks created from document: 8
- Inserting vectorized chunks into Chroma collection.
- Caching vectorized results of custom-documents/techsquad-f8dfa1c0-82d3-48c3-bac4-ceb2693a0fa8.json to prevent duplicated embedding.
此功能使我们能够与文档进行交互式对话。 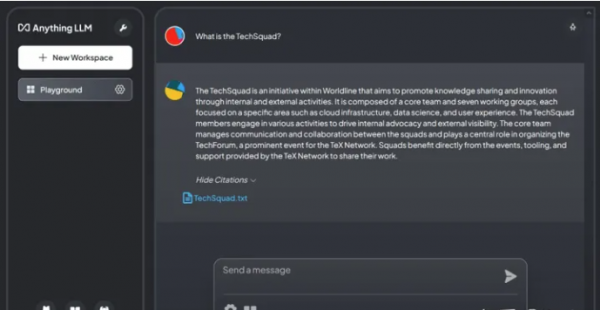 AnythingLLM 的一个有趣功能是它能够显示构成其响应基础的内容。 AnythingLLM 的一个有趣功能是它能够显示构成其响应基础的内容。
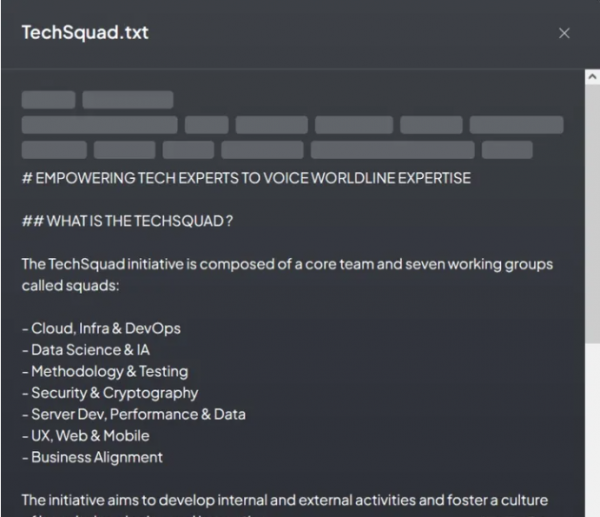
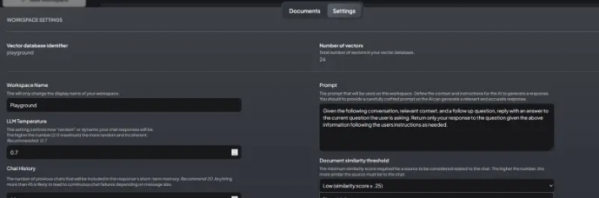
总之,AnythingLLM 及其中的每个工作区都提供了一系列可配置参数。其中包括系统提示、响应温度、聊天记录、文档相似度阈值等,从而实现定制化、高效的用户体验。
3.4、安装和配置 Vector Admin为了完成我们的架构,我们现在专注于安装 Vector Admin GUI,它是一个强大的工具,用于可视化和管理 AnythingLLM 在 Chroma 中存储的向量。 安装过程涉及利用 Mintplex Labs 提供的 Docker 容器:一个用于 Vector Admin 应用程序,另一个用于 PostgreSQL 数据库,该数据库存储应用程序的配置和聊天历史记录。 - git clone https://github.com/Mintplex-Labs/vector-admin.git
- cd vector-admin/docker/
- cp .env.example .env
- SERVER_PORT=3002
- DATABASE_CONNECTION_STRING="postgresql://vectoradmin:password@127.0.0.1:5433/vdbms"
此外,我们配置 SYS_EMAIL 和 SYS_PASSWORD 变量来定义第一个 GUI 连接的凭据。 鉴于默认端口的更改,我们还在 docker-compose.yaml 和 Dockerfile 中反映了此修改。 配置完后端之后,我们将注意力转向前端安装。 - cd ../frontend/
- cp .env.example .env.production
- GENERATE_SOURCEMAP=false
- VITE_API_BASE="http://127.0.0.1:3002/api"
- docker compose up -d --build vector-admin
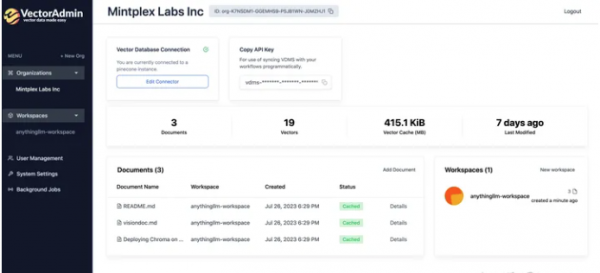
通过 http://localhost:3002 访问 GUI 非常简单。初始连接使用 .env 文件中指定的 SYS_EMAIL 和 SYS_PASSWORD 值。仅在首次登录时需要这些凭据,以从 GUI 创建主管理员用户并开始配置该工具。 GUI 中的第一步是创建组织,然后建立向量数据库连接。对于数据库类型,我们选择 Chroma,尽管 Pinecone、QDrant 和 Weaviate 也是兼容的选项。 同步工作区数据后,存储在 Chroma 内“playground”集合中的文档和向量变得可见。 这些载体的详细信息也可用于深入分析。 关于功能的说明:直接通过 Vector Admin 编辑向量内容目前受到限制,因为它利用 OpenAI 的嵌入模型。由于我们选择了 s-BERT MiniLM,因此此功能不可用。如果我们选择 OpenAI 的模型,上传新文档并将向量直接嵌入到 Chroma 中是可能的。 Vector Admin 还拥有其他功能,如用户管理和高级工具,包括相似性搜索中的自动偏差检测、即将推出的快照以及组织之间的迁移功能(以及扩展后的 vectostores)。 该工具特别令人钦佩的是它能够完全控制载体,从而大大简化其管理。 四、总结至此,我们对Mintplex Labs的AnythingLLM和Vector Admin进行了全面探索。这些工具简化了RAG模式的设置流程,并使得与文档的对话交互成为可能。随着这些项目不断进化,新功能也在不断推出。因此,关注他们的更新并开始使用这些工具来交互式处理您的文件将是一个明智的选择。 五、References
| 




 发表于 2024-2-27 13:10:01
发表于 2024-2-27 13:10:01


 扫码关注微信公众号,及时获取最新资源信息!【
扫码关注微信公众号,及时获取最新资源信息!【